使用Ruby写一个Racket(Scheme)解释器
如果学习Lisp系语言,可能在后期都会实现一个本语言的解释器interpreter来练个手。
我学的是 Lisp(或者说Scheme)
方言之一的Racket,自己当时能写解释器的时候的确感觉不一样。
毕竟之前也接触过很多语言,基本都是学的语言特性feature,和其流行的package使用(比如web框架)。很少接触过语言实现language implemention的知识。
当自己能写出解释器的时候,感觉到一种新的学习语言的体验。
这篇文章努力做到新手友好,只需要有一定编程知识基础(可能只要懂一门语言)即可阅读。
项目github链接:https://github.com/mixflow/RacketOnRuby/
https://github.com/mixflow/RacketOnRuby/
语言相关介绍
Ruby现在还算有些名声,现在的程序员即使没用过的,可能都知道有这门语言。
但是Lisp Scheme可能很多程序员都没听说过,
我当年阅读了别人推荐的《黑客与画家》
这本书才有所了解,在此之前我似乎连Lisp或者Scheme的名字都没见过。
所以有必要先简介一下。
Lisp Scheme Racket 是什么?
Lisp是一门诞生于上个世纪50年代的语言。其后有很多相同思想的语言,都算得上Lisp家族的,一般被称为Lisp
方言dialect, 其中就包括这里提及的另外两个语言Racket
Scheme。Scheme年代更加久远,影响也大些。Racket相比之下更年轻些。
这篇文章只涉及语言基本简单特征实现,这块哪怕语法上面Racket Scheme都没什么区别, 所以这里的Racket解释器也可看作Scheme解释器。也就是说能解释执行Scheme代码。
Why use Ruby?
- 当时正好也在学Ruby,所以就用Ruby实现下,纯练手。
- 这个是第二个编译器实现。最早第一个是当时学习Racket的时候,使用Racket本身实现的,编写了一个
metacirclar evaluator,这种方式可以跳过parse步骤(详见紧接着的下文),因为写的代码就已经是AST了(依旧详见下文)。那么用Ruby来实现Racket的话,是需要parser,所以也能再多练一些(虽说parser也没什么复杂的)。 - 《黑客与画家》中
“如果回到1975年,你声称它(Ruby)是一种有着自己语法的Lisp方言,没有人会提出反对意见。”。
作者认为Ruby也可以视为Lisp的一种方言。那么我反过来通过Lisp的方言来实现Lisp,想法有些古怪,但我认为有点意思。
实现一个编程语言通常的步骤
下面涉及的是一个典型的语言实现language implemention的流程:
- 首先接受一串字符串
string,其内容就是用此语言编写的程序。如果该字符串不是符合语法结构syntactically well-formed(比如关键字拼写错误等),分析器parser会报错。 - 如果没有上述的语法错误,parser会生成一个树
tree来表示程序。这个树一般称为abstract-syntax tree,简称为AST。- 如果语言有
类型检查 type-checking或其他原因,认定AST仍然不是一个合法的程序。类型检查器 type-checker就会生成错误信息。 - 如果没有上述错误, AST就会被传递给后续流程。
- 如果语言有
- 实现目标编程语言
language B的剩余流程,基本就是如下两种方案。- 可以用另一门语言
language A编写解释器 interpreter来接受使用language B编写的程序,并最终产生结果。这里用来实现interpreter的language A,有个专门术语称呼:metalanguage。
如果把这个
language A程序称作evaluator for B(evaluate中文对应术语一般叫求值,大概意思达到了,但我个人觉得不太准确)或者执行器 executor for B,可能会更直白些。但解释器 interpreter是约定俗成的术语。- 另外一种方式再
language A写一个编译器 compiler来将language B写的程序生成一个等价equivalentlanguage C的程序。 然后再使用早已存在的language C语言实现。
编译器 compiler可能称为翻译器 translator更好,与interpreter同样的原因,compiler是个普遍使用的术语。 - 可以用另一门语言

另外要说教下,编译器以及解释器只是编程语言实现方式的特征the feature of a particular programming language implementation,而不是编程语言自身的特征the feature of the programming language。所以“编译性语言” compile language 或者“解释性语言” interpreter language 的说法完全没有意义。完全可以给Lisp,Scheme系语言编写一个compiler(这些语言的解释器实现比较常见),给C语言编写一个解释器也是完全可行的。
Racket基本语法以及parser实现
建议先在Racket官网下载原生Racket以及配套IDE DrRacket,写Racket或者Scheme程序方便些。 另外本文interpreter实现基本不包含检测和错误处理,所以测试代码最好先在原生Racket里面执行下。
需要快速了解Racket基本语法,推荐此篇快速介绍文章Learn X in Y minutes, When x = Racket。
代数运算
(+ 2 (* 2 3))先来个简单的Racket代码例子,上述代码较内层括号(* 2 3)是乘法运算,然后在外层括号内再将上述乘法运算结果加上2。
整个代码等价于数学或者常见编程语言2 + 2 * 3代码意义。
一开始就比较不同寻常,对于此类Racket代码可以看作操作符 operator以及操作数 operand的组合,再用括号包裹。比如(+ 1 1)就可以把+看作操作符。另外可以括号形式的代码嵌套,比如上述先乘后加的代数运算。
这种代码形式,实际非常简单,我们可以给一个更加明确的定义如下节。
Racket所有的东西都是:
就两种!
- 一个
atom,比如数字3、字符串"hello"、#t、#f、null。也包括一种atom的:识别符 identifier,可以是变量variable,
或者是特别形式special form诸如define、lambda、if。(涉及的名词或者术语,不理解没关系,再后文会一一介绍) - 或者是在括号的一序列sequence东西
(t1 t2 t3 ... tn)。
该定义还有个专门的名称S-expression,随着Lisp诞生给出的定义用来描述Lisp。
详说下第二种情况。括号里的第一东西t1,影响余下的序列中的东西。
如果是special form,比如define,以为定义一个东西,要么是变量variable,要么是函数function(lambda)。
如果不是special form,剩余情况一般是函数执行function
call,很多东西在Racket里都是函数,比如加减+和-。
在Racket里括号是很常见的,而且括号作用非常明确。不会遇到f x y是(f x) y还是f (x y)的疑惑。
Racket的括号直接影响着解析parsing,将代码转换成树形结构。实际上Racket代码本身就是树形结构。
如果没有了解过Lisp系语言,大部分人看到一段比较长的代码,都会觉得充满了括号的怪异语法。如果能抛开这些成见,学习使用后实际上能很快适应。
Token
具体到parser中第一步生成token token generator或者叫词汇分析lexical Analysis。可以参照上文实现语言通常流程小节引用的流程图,其中’parser’部分。
这个过程就是把代码字符串分割成多个有意义的符号。这个过程一般使用正则表达式regural
expression简称regex。这些符号专门的术语就是token。
# write token generator on ruby
class Racket
def tokenize(str)
str.gsub("(", "( ") # add space after '('
.gsub(")", " )") # add space before ')'
.split(" ") # split string into an array(tokens) base on whitespaces
end
end快速简介下ruby,本文在前言里面提及了面向新手,所以会对于不了解ruby的读者涉及一些介绍,这部分内容我会用引言块注明(如下),如果不需要,随意跳过。 不光会有ruby知识,还有一些别的编程知识。
Ruby是一种
动态类型dynamic type面向对象object oriented编程语言。我定义了一个名叫Racket的类class。 其中定义了一个名叫tokenize的函数。函数有一个’str’的参数,用来接收代码字符串。注意class和method都使用了end明确表明各自代码块的结束部分,ruby里面大部分代码快都需要end结尾,比如if。
另外ruby函数会自动返回最后一个对象。当然你也可以明确explicitly使用return,比如条件(if)分支需要返回的情形。
代码很简单,先将这对括号”()“内测增加一个空格,方便最后分割split操作。gsub便是替换操作。
str.gsub(...).gsub(...).split(...)这种连着执行函数模式,术语叫做chaining。自己写的代码函数返回对象即可做到。
另外这种风格并不是ruby或者别的某个语言特有的,是一种习惯用法idiom。好处就是少些变量名或者赋值,另外也没必要构造一个大而全方法,完全可以构建更合理多个方法并连续调用从而达到目标。
下面便测试下上述代码
使用系统的命令行工具到相应的代码目录。确保安装ruby后输入irb命令,定义一段代码string,传入tokenize函数生成token。
# Test Tokenize in irb
c:\Projects\RacketOnRuby>irb
irb(main):001:0> load 'racket.rb'
=> true
irb(main):002:0> r = Racket.new
=> #<Racket:0x00000002e67df8>
irb(main):003:0> str = %{(+ 1
irb(main):004:0" (* 2
irb(main):005:0" (- 7 3)))
irb(main):006:0" }
=> "(+ 1\n (* 2\n (- 7 3)))\n"
irb(main):007:0> p r.tokenize(str)
["(", "+", "1", "(", "*", "2", "(", "-", "7", "3", ")", ")", ")"]
=> ["(", "+", "1", "(", "*", "2", "(", "-", "7", "3", ")", ")", ")"]
- 第1行(最左边的行号)
irb进入ruby REPL。没听过REPL,先粗略认为REPL就是专门执行代码的命令工具。下文REPL章节会详细的涉及,因为我们实现Racket也要写个Racket的REPL,来方便测试。- 第2行加载包含Racket class的相应的ruby file。 我的ruby文件名就叫做racket.rb。
- 第4行创建一个Racket的对象
实例instance。该实例将来调用相应的函数进行tokenize以及后续的操作。Ruby的语法syntax,很多时候执行函数都可以省略括号,比如此处创建对象的时候调用new构造函数,可选写法:Racket.new()两种代码等价的。- 6行到9行,定义了变量名为
str的code string。%{...}是ruby定义多行字符串的一种语法syntax。- 第10行,irb会自动输出之前代码执行结果返回的对象(包括之前的3、5行)。其中把换行转义成了’’输出在一行。
- 第11行,调用
tokenize函数,并传入上一步定义的string。并打印输出结果即tokens
可以把上述命令行中的ruby测试代码放入专门的rb文件,这样就无需在每次重新测试再敲代码。例如github项目中的example.rb,直接系统命令行执行
ruby example.rb
此前代码,在tokenize函数多了第一步处理是把多个空白符转化成单个隔空”
“,然而写这篇文章的时候,我重新审查了下代码,并不需要多此一举。多余的代码:str.gsub(/\s{2,}/, " ")
原因是split方法传入单个空格字符串的时候,会基于空白符whitespace分割,而且会忽略余下的紧挨着的空白符。1
token生成好了,下面便是分析token并生成AST了。
Abstract Syntax Tree (Parse Tree)
def generate_ast(tokens)
def aux(tokens, acc)
if tokens.empty?
# no tokens left, return result
return acc
end
token = tokens.shift # get first token
if '(' == token # start one s-expression
sub_ast = aux tokens, []
acc.push sub_ast
aux(tokens, acc) # recursive call to continue handling rest tokens
elsif ')' == token # end one s-expression
return acc
else
acc.push atom(token) # convent current token to atom
aux tokens, acc # recursive
end
end
aux tokens, [] # initial call helper
end真正起作用的是generate_ast内部定义aux(auxiliary辅助,
helper)的方法,处理tokens,其参数acc(accumulator累加器)存放的处理得到的AST。
主要使用递归 recursion从左到右处理tokens里面的每一个token:
- tokens为空的时候,返回
acc即AST结果。 - 当遇到左括号时,说明遇到一个s-expression的序列,递归调用
aux方法的时候给acc参数传入一个新的空array(上述第10行代码),用来存储这部分subdivision s-expression序列对应的AST结果。
第11行,递归调用处理完返回subdivision acc结果,追加到原来acc后面。 - 当遇到右括号的时候,说明s-expression的结束,返回结果
acc,对应上一点的subdivsion acc。
- 剩余其他情况,将token转化为atom,紧接的下文涉及atom实现细节。
实际generate_ast方法简化下就是匹配括号的代码,包括嵌套nested结构。
上述代码并没有检测括号是否匹配,因为需要文章简洁,这里只贴出不检测括号的代码,github上面的源文件里面包含有完整的括号检测。
racket里面除了可以使用圆括号(),也可以使用方括号[],两者功能作用没有区别,编码习惯在某些地方会使用[],但不遵循也不会有什么实质影响。唯一注意的就是要对应的括号匹配,不能混用,比如(+ 1 1]就是语法不正确。
Atom
# s-expression atom
def atom(token)
str_part = token[/^"(.*)"$/, 1] # try match string(start and end with ")
if not str_part.nil?
str_part
elsif token[/(?=(\.|[eE]))(\.\d+)?([eE][+-]?\d+)?$/] # decimal
token.to_f
elsif token[/^\d+$/] # integer
token.to_i
else # symbol
token.to_sym
end
end刚才上文我们已经处理了s-expression序列,即上文提及s-expression第二种情形。此处atom为第一种情况,具体又有细分,可能是string、数字、也有可能是identifier。对应代码中if语句各个分支,通过正则式尝试匹配token(Ruby
string对象):
在Racket中头尾各一个双引号
"来包含字符串。第一个if便是通过正则式匹配首尾”,如果的确是string,其中间部分取出就是对应的Ruby string类型的对象。第二个if分支判断是否为浮点数。这里的正则式看起来很复杂,简单代替方案是仅仅匹配小数点(正则式为
/\.\d+$/)。这里复杂的正则式是除了用来匹配小数外,还能匹配指数exponential,Ruby中指数类似1e5也算作浮点数(等同于10000.0,Racket中也是同样的)。to_f便是将string转化为float浮点数的方法。这里举出4个数.0030.532e3.24e5,这些都是浮点数,我们的正则式便是能够匹配出对应小数点部分以及指数部分,测试代码如下,第一行这四个数尝试使用该正则式匹配,第二行是匹配部分的结果:ruby # decimal and exponential ['.003', '0.5', '32e3', '.24e5'].map{|num| num[/(?=(\.|[eE]))(\.\d+)?([eE][+-]?\d+)?$/] } # => [".003", ".5", "e3", ".24e5"]> Ruby Array的map方法,是将其中每个元素都进行block中处理。{ |num| ...}形式就是block,此处Array.map会往block的num参数 传入单个元素。第三个if分支,尝试匹配是否为整数。to_i便把string是转化整数integer的方法
最后一个else分支,剩下情况可能是变量名或者special form比如
lambdadefine等。最后转化为Ruby符号Symbol类型。所谓symbol类似string,symbol为不可变immutable,而且其值一样的话,就是同一个对象。Ruby中symbol是以
:作为开头,例如:hello。两两比对的时候symbol效率更高。不像string一个一个字符char进行比对,symbol直接比对两者在内存中是否为同一个对象。
到此为止,实现了生成AST的部分,下面就要涉及interpreter部分了。
eval方法实现executor(interpreter)
有些表达式expression中会包含变量variable,求值evaluate这些表达式就需要environment,通过variable获得对应值vaLue。
environment的实现是metalanguage的一部分,metalanguage这里就是我们使用的Ruby。这里使用hash数据结构来代表environment。
完成代数运算eval
文章一开始的提及的代数运算的Racket代码(+ 1 (* 2 3)),首先将其实现:
# eval algebra operators
def initialize()
@env = {
:+ => lambda{|x, y| x+y},
:* => lambda{|x, y| x*y}
}
end
def eval(exp, env=@env)
if exp.is_a? Numeric
exp # is a number(integer and float) return itself
elsif exp[0] == :+ or exp[0] == :*
env[ exp[0] ].call( eval(exp[1], env), eval(exp[2], env) )
else
results = exp.map { |subexp| eval(subexp, env) }
results[-1]
end
end增加了两个方法initialize以及eval。
initialize方法是Ruby的对象的构造器方法,即new对象时候会调用该方法,该方法可以省略,我们之前parser部分就不需要构造方法,所以就一直没有initialize。
Ruby中
@开头的变量是实例变量instance variable,作用范围为单个对象实例内,所有该对象的内部方法都可以访问到。
另外@@两个at符号开头是类变量class variable,顾名思义即同一个类创建的所有对象实例 都共享同一个类变量。
Ruby不需要提前声明variable,赋值一个之前不存在的variable,会自动创建该variable。
其中initialize方法中,定义了一个@env实例变量,并赋值了一个hash。之前说过,在Racket中代数运算看作函数,metalanguage(Ruby)实现了+和*各自对应的lambda(或者叫Proc
object,ruby的术语),lambda可以看作匿名函数,该匿名函数接受两个参数x``y,将其相加或者相乘。
后文还会详细介绍lambda,因为我们也要实现Racket的lambda,Racket和Ruby的lambda基本是同一个东西,仅语法有区别。
eval方法依旧含有recursive call,递归很适合处理嵌套形式,处理 子表达式subexpression,需要返回的情形结果可能有差异。
- 第一个if条件分支,判断如果表达式只是纯粹数字,那么不需要额外处理,返回自身。
- 第二个条件分支,涉及expression的首个thing如果是
:+或者:*,env[ exp[0] ]则去environment中查找对应的函数。调用传入expression紧接着的2个thing,作为两个操作数。注意此处都会先执行下eval方法,因为可能是需要处理的subexpression,同时也是使用的同样的environment。 - 最后一个条件分支,之前实现的parser实际上可以处理多个expression,例如
(+ 1 1) (* 2 2) (+ 3 4)这样的代码中包含三个expression,parser处理完后的AST为[[:+, 1, 1], [:*, 2, 2], [:+, 3, 4]],包含三个expression处理后的AST的array。即使只有一个expression,parser处理后也是一个长度为1的array,例如该章开始提到的代码,parse后的结果:[ [:+ 1 [:* 2 3]] ]。
这里,我返回的最后一个结果。当然也可以直接放回results结果array。自己写的interpreter,细节由自己定义。
Function call以及Variables in environment
上面处理加和乘,可以改写成处理任何方法的通用办法.
# updated call functions
def eval_expressions(exps, env=@env)
results = exps.map { |one_exp| eval(one_exp, env) }
results[-1]
end
def eval(exp, env=@env)
def lookup_env(env, var)
error_no_var = "undefined: \"%s\"" % var
val = env[var]
if val.nil?
raise error_no_var
else
return val
end
end
if exp.is_a? Numeric
exp # is a number(integer and float) return itself
elsif exp.is_a? Symbol
lookup_env(env, exp)
else
operator = eval(exp[0], env) # first thing of s-expression sequence.
operands = exp[1..-1].map {|sub_exp| eval(sub_exp, env) } # the rest things of sequence
operator.call *operands
end
end将处理多个expression的办法提炼成eval_expressions方法。这样的话parse处理完后的AST(结果都是array,一个或多个expression)就先调用eval_expressions处理。而eval只用来处理单个expression。这样处理的理由,如果包含在eval一个条件分支的话,会与单个expression处理混乱(因为同样使用array来存放s-expression)。
else分支就是处理方法调用,expression第一个thing也执行了eval。这样就可以处理这样的( (if #t + *) 2 3 )Racket代码(第一个thing也可能是sub
expresion)。
operator.call *operands中oprands是array,其前面*是splat operator。作用是将数组拆开,每个元素对应到单个参数。反过来,在函数参数声明时候也可以使用*,作用也是相反的,将传入的单个参数值组成array。
另外,多了处理symbol
atom的步骤,一般symbol为variable的时候,就需要到environment查找对应的value,即lookup_env方法。该方法很简单,就是通过variable作为key查找environment对应的值,没有variable的话就抛出一个简单错误提示该variable没被定义。
如果完整代数运算,除法和减法:/,:-可以类似上面写法。但是重复劳动了,用程序来做重复的事。另外还有一点需要改进,Racket中代数运算符,可以接受多个数字,进行累积运算。
例如(+ 1 4 5 7)执行结果为17,(* 2 3 4)执行结果为24。
# updated algebra
ALGEBRA_OPERATORS = [:+, :-, :*, :/]
def initialize()
@env = {
}
ALGEBRA_OPERATORS.map do |opt|
@env[opt] = lambda{ |*operands| operands.inject(opt) }
end
end改写成上述代码,通过程序往environment增加每个代数运算符对应的lambda函数。看到这似乎炫技嫌疑,但实际后面也有相同的思想的实现,比较大小的comparison operator也是类似的(也是能接受多个参数)
至此eval的大致结构功能如此。后文涉及的新的Racket
feature,就是往eval增加更多情况的处理,方式可能是增加条件分支,也有可能是往environment中增加函数(可以看作Racket自带的函数)。
工具REPL, Read-Eval-Print-Loop
在继续完备eval方法之前,首先实现REPL这个工具,让调试Racket代码更加方便。就如之前执行Ruby代码的irb。
REPL全称read-eval-print-loop顾名思义,其过程: 读取code ->
eval求值这段代码 -> 输出结果 -> 循环上述步骤。
# REPL
def repl(prompt='RacketOnRb >>', output_prompt="=>")
while true
print prompt
code = gets
begin
ast = parse(code)
result = eval_expressions(ast)
puts output_prompt + result.to_s
rescue Exception => e
puts e
end
end
end相当直接的代码,一个无限循环,接受console输入Racket代码,然后解析执行代码,即之前描述的过程。
执行parse,eval这部分时,会尝试捕获异常,如果有异常只是打印出来,继续loop。这样就能避免出错整个program终止,需要重新执行该repl方法。
定义变量variable
前面已经完成查询variable对应的value的方法。相应我们需要实现定义变量,其语法(define <var> <exp>)。
elsif exp[0] == :define
_, var, value_exp = exp
env[var] = eval( value_exp, env )放置于处理function call分支之前即可。
条件判断、if语句
Racket中用#t和#f表示true和false。
Racket
if的语法:(if <test-exp> <then-exp> <else-exp>)当#f的时候,执行<then-exp>分支,否则执行<else-exp>分支
@env = {
:'#t' => true,
:'#f' => false
}
# ...
elsif exp[0] == :if
_, test_exp, then_exp, else_exp = exp
if eval(test_exp, env) == false
eval( else_exp, env )
else # other than false(#f)
eval( then_exp, env)
endruby注释使用#,如果symbol含有#的话,需要用引号括起来。这里会把Racket的#t #f转化为Ruby中的true和false。
比较操作comparison operators
至于比较操作,上文提过了类似代数操作实现。
当有多个需要比较的对象时,比较操作需要两两比较,所有两两比较结果为true,则返回true,否则false。
each_cons(n)就是(Ruby提供方法来遍历连续consecutive的n个元素)。2
# comparision
COMPARISION = [:==, :!=, :<, :>, :<=, :>=]
def initialize()
# ...
COMPARISION.map do |opt|
@env[opt] = lambda{ |*args| args.each_cons(2).all? {|x, y| x.method(opt).call(y)} }
end
endRuby和其他大部分语言,使用=代表赋值操作,所以比较是否相等时候使用==。但是Racket有专门的define操作,所以依旧使用=代表比较是否相等的函数。
我追求简单,所以实现套用Ruby语法。如果要改为Scheme
Racket语法也很简单,多做一次符号映射即可,其他不做赘述了。
Cons Cell and List
cons操作用来构建一个pair,其通过car获得pair的第一个数据,通过cdr获得pair的第二个数据,pair有专门的术语:cons cell。
另外Racket有个特许且常用的cons cell形式:list,例如(cons 1 (cons 2 (cons 3 (cons 4 null))))代码,nested
cons
cells,最后一个(最内部的pair)的第二数据以null为结尾。
null在Racket中代表空list,null?判断是否为空的函数。list有个更加简便的写法(list 1 2 3 4)等同上行的代码例子。
| Primitive | Description | Example |
|---|---|---|
| null | The empty list | null |
| cons | Construct a list | (cons 2 (cons 3 null)) |
| car | Get rst element of a list | (car some-list) |
| cdr | Get tail of a list | (cdr some-list) |
| null? | Return #t for the empty-list and #f otherwise | (null? some-value) |
对于Ruby实现代码,我们使用array来存放cons cells,固定两个元素。
对于list函数实现,依旧采用recursion方式,cons(直接构造Ruby
array)第一个参数以及余下参数构成的list,很直白实现方式。
# cons cells
:null? => lambda { |exp| :null == exp }, # racket empty list.
:cons => lambda { |x, cell| [x, cell] },
:car => lambda { |cell| cell[0]},
:cdr => lambda { |cell| cell[1] },
:list => lambda do |*args|
# racket code '(list 1 2 3)' is equivalent to '(cons 1 (cons 2 (cons 3 null)))'
racket_list_helper= lambda do |args|
if args.empty? then :null
else [args[0], racket_list_helper.call(args[1..-1])]
end
end
racket_list_helper.call(args)
endFunctions,Lambda and Apply
问题弄清楚后,答案自然就清楚了。
到了我觉得最重要的function部分了。目标实现function,只需要搞清楚何为function就知道如何实现,首先先要明确一些相关的概念。
Racket的函数遵循lexical scope又称作static scope,函数的正文部分求值时,所用的environment在该函数被定义时候的enviroment。相对立的dynamic scope,就是函数求值时,使用的函数被调用的enviroment。
The body of function is evaluated in the environment when the function is defined, not the environment when the function is called.
现在主流编程语言基本都是使用lexical scope,程序行为更可控。
除了定义的时候的environment,方法执行的时候,还会将该environment扩展添加参数parameters以及其对应传入的值arguments。
function(或者叫lambda, procedure)的实现代码如下,存放lambda的parameters和body,以及定义时候的envrioment,就如同上文描述那样。
定义了Closure
class,只是用来存放closure的值。也可以用数组[:closure, parameters, body, env]存放,通过index取值,但是这样的话:closure可以被覆盖。
真正执行部分,处于之前执行方法部分,之前处理例如加法之类的primitive procedures。现在增加分支专门处理,用户定义的函数compound procedures。 操作数部分与之前一样,先eval,然后补充进函数定义时的environment。该environment为执行函数体body的环境,然后求值。
# closure handle
class Closure
attr_reader :parameters, :body, :env
def initialize(parameters, body ,env)
@parameters = parameters
@body = body
@env = env
end
end
def eval(exp, env)
# ... other part code
elsif exp[0] == :lambda
_, parameter_names, fun_body = exp
Closure.new(parameter_names, fun_body, env)
# ... other part code
else # call function
operator = eval(exp[0], env) # first thing of s-expression sequence.
operands = exp[1..-1].map {|sub_exp| eval(sub_exp, env) } # the rest things of sequence
if operator.is_a? Closure # compounded procedures(user-defined)# extends environment with parameters and their actual arguments applied.
env_fn = operator.parameters.zip(operands) + operator.env
body = operator.body
eval(body, env_fn)
else # primitive operators
operator.call *operands
end另外environment有了较大的改动,之前使用hash结构,在写这篇文章的时候,我重新审查代码时候,发现有较大缺陷:
- 之前hash结构,define定义新变量是直接更改该hash本身,mutation操作。定义lambda的时候,最初直接传入env本身,然而因为hash是可变的,所以实现的是
dynamic scope方式,后续对env操作也会影响函数定义是当前的env(就是同一个对象)。 - 我最初的处理方法是,对于函数定义时候的env,使用一个新的对象
env.clone。似乎解决了问题,但是在某些simultaneous同时发生,比如需要两个方法同时定义,如果通过env.clone,两个方法的env是两个独立对象,然而我们需要两个方法env都是同一个对象,因为它们处于并列状态,例如letrec(不是本文重点,但代码中有实现)。
所以,需要改变的是:
- define添加新的variable到当前env(并不改变原先env)作为新的env。相当于新的environment是immutable。
- 定义lambda的时候,直接使用当前的env。
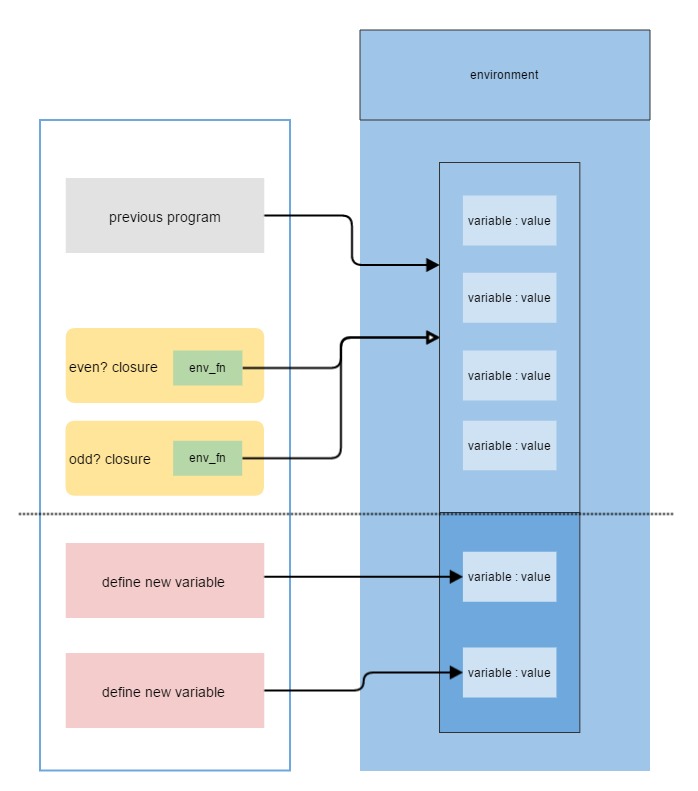
对应到ruby代码实现。使用array取代hash,其中每个元素即变量和其对应的值(2个元素的array分别存variable,value)。
define时候通过 env[0..-1]
重新赋值env。由于现在需要直接更改当前的environment,而且ruby不支持参数传入引用,所以我使用env[0..-1] = [new array]将env内的array中的元素替换成新的env(包含新定义的variable),来达到更改当前environment目的。
# new environment
@env = [
[:'#t' , true],
[:'#f' , false],
# Racket 'not' operator if exp is #f, results #t. otherwise false. it differents from ruby not
[:not , lambda { |exp| if false==exp then true else false end }],
# ... other primitive procedures.
]
def eval(exp, env=@env)
def lookup_env(env, var)
error_no_var = "undefined: %s !" % var
var_val = env.assoc var
if var_val.nil?
raise error_no_var
elsif var_val[1] == UNASSIGNED_VAL
raise "the unassigned value should not be access."
else
return var_val[1]
end
end
# ... other eval parts
elsif exp[0] == :define
_, var, value_exp = exp
value = eval( value_exp, env )
env[0..-1] = [[var , value]] + env
# ... other eval parts
end # eval至此,最重要的lambda部分就已经完成实现了。
RacketOnRuby总结
出于练习目的,实现Racket的一个解析器。从功能完整性和性能考虑,并不适合实际生产中运用。
得益于Racket语法统一简单,实现也相对简单。不像很多别的语言,有大量不同形式的语法。
- 相对于原生Racket,肯定缺少一些功能,但常见的基本都实现了。
- 实现了environment、variable、condition(if)、 lambda、 cons cells、 list、 一些primitive procedures(代数运算,数值比较)。
- 语法缺少的:注释comment、 quote、 # symbol(字面量类似Ruby symbol)、 一些derived expression(可以转化为现有的别的表达式,例如cond用来多个条件判断,可以转化为嵌套的if)
- 项目中代码是实现有
let和letrec,也是derived expression。(let ([<var> <exp>]) body)其作用就是绑定local variable,并在其environment执行body部分代码。let可以转为lambda,letrec可以转为一种特殊形式let。转化方法是直接操作AST,由于Ruby中AST用的Array表现,并不是那么清晰,所以不做本文重点。(相对于metalanguage使用Lisp系语言,Lisp系语言code即data,代码部分也可以操作,即可以直接在程序expression上直接操作) - 缺少大量primitive
procedures,语言肯定会有大量自带的函数,不可能一一实现。其中之一就是mutation
list,Racket的默认list是不可变的immutable。如果需要可变的,有专门的操作:
mcons,set-mcar!,set-mcdr!。这一点也是Racket与Scheme不同的一处,Scheme中list是mutation list。 - error handling不是主要目标,所以几乎没有异常错误处理,所以需要执行的program先要保证正确的。可以DrRacket先执行一遍,尤其括号方面(多或者少,不匹配),IDE可以很明显看出括号范围。
- 性能方面,也不是主要目标,没有特别优化。下面指出一些可以改进的地方:
eval实现,实际上语义分析syntactic analysis夹杂在执行execution之中,不是有效率的做法。如下阶乘的program,当执行(factorial 5),递归调用factorial多次,其中if部分每次都需要判断出是if,但执行到(* (factorial (- n 1)) n)))其中(- n 1)和(factorial (- n 1))都需要在eval判断出是方法执行然后再处理。非常重复浪费的做法,需要将analysis分离出来,本文并没涉及,具体实现可以参考SICP3第四大章中Separating Syntactic Analysis from Execution小节部分
(define (factorial n) (if (= n 1) 1 (* (factorial (- n 1)) n)))- 缺少
TCOtail call optimization,尾递归优化,Lisp和Scheme系的语言program非常依赖与递归调用,TCO非常重要,能省去很多function call占用的stack空间。
要想了解interpreter如何工作,最好办法就是自己实现一个了,这就是我实现RacketOnRuby以及写本文的目的。 如果需要更深入了解,推荐上文提及SICP以及另外一本书TSPL4,都是有免费阅读的电子版。或者自行搜索,有相当多的资料。
另外文章最开始提及的《黑客与画家》,非编程技术书,也推荐阅读。语言通俗易懂,不涉及技术细节,阅读不费力,非程序员也能读。但其中作者的思想条理清晰,观点深入透彻。另外本书也不光全是关于Lisp,还有一些有趣事情,我印象较深的就是最开始的章节”为什么书呆子不受欢迎”。
{# > The prefixes #b, #o, and
#x specify binary, octal, and hexadecimal interpretation of
digits
implemention on Racket environment using cons (benifit sharing small part due to immutation)
#}
Ruby Doc: String.split: If pattern is a String, then its contents are used as the delimiter when splitting str. If pattern is a single space, str is split on whitespace, with leading whitespace and runs of contiguous whitespace characters ignored.↩︎
Ruby Doc Enumerable each_cons(n): Iterates the given block for each array of consecutive
elements. If no block is given, returns an enumerator.↩︎ Structure and Interpretation of Computer Programs MIT scheme课程书籍. ↩︎
The Scheme Programming Language http://www.scheme.com/tspl4/. ↩︎